■ eclipse에서 maven plugin을 이용한 간단한 hadoop 프로젝트를 생성하고 svn에 소스를 커밋하고 jenkins를 이용해서 빌드 및 배포 후 hadoop을 실행하는 방법을 알아보고자 한다.
■ Eclipse 메뉴 > File > New > Other…을 선택한다.
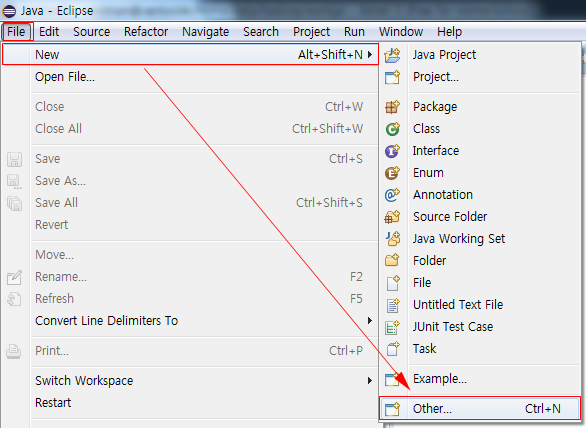
■ Project 마법사 메뉴에서 Maven > Maven Project를 선택하고 Next 버튼을 선택한다.
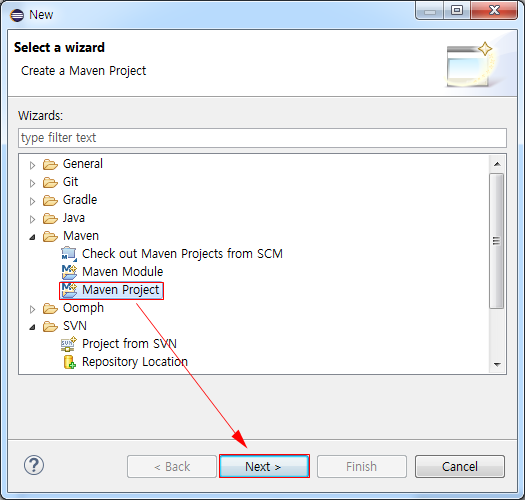
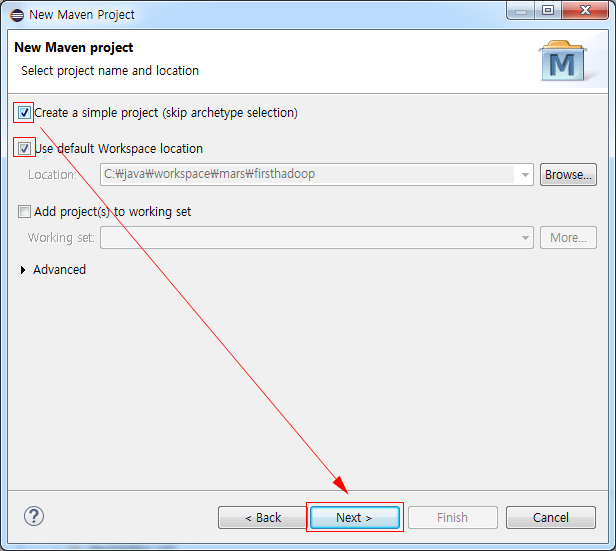
■ New Maven project에서 Create a simple project(skip archetype selection)을 체크하고 Next 버튼을 클릭한다.
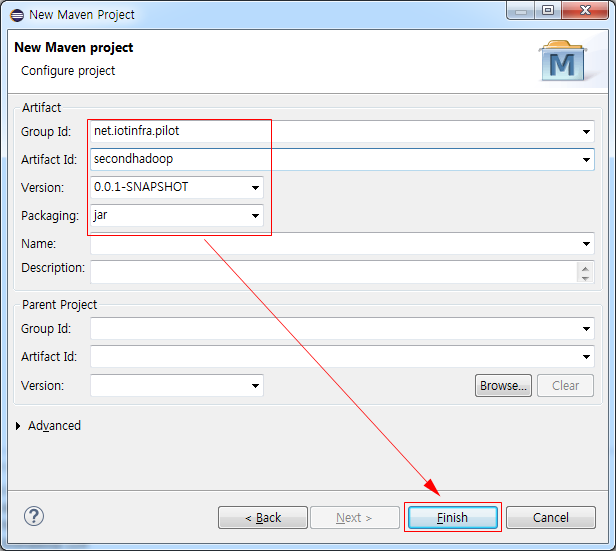
■ Group Id, Artifact Id, Version은 사용자 임의로 입력하고 Packaging는 jar를 선택하고 Finish 버튼을 선택한다.
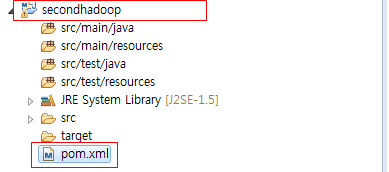
■ 완성된 hadoop용 프로젝트의 구조가 Package Explorer에 표시되었다.
■ secondhadoop프로젝트의 pom.xml을 편집한다. hadoop-core, hadoop-mapreduce-client-core의 dependency를 추가하고 jdk.tools를 hadoop-mapreduce-client-core dependency에서 제외한다. 제외하지 않으면 Missing artifact jdk.tools:jdk.tools.:jar:1.7 에러가 발생한다.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.iotinfra.pilot.hadoop</groupId>
<artifactId>firsthadoop</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<hadoop.core.version>1.2.1</hadoop.core.version>
<mapreduce.client.core.version>2.7.2</mapreduce.client.core.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>${hadoop.core.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${mapreduce.client.core.version}</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</project>
■ secondhadoop프로젝트에서 net.iotinfra.pilot.hadoop 패키지를 생성하고 패키지 안에 WordCount.java 클래스를 추가한다. 추가한 소스의 출처는 Hadoop MapReduce Tutorial의 예제 코드이다.
package net.iotinfra.pilot.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(
Text key,
Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
■ 완성된 프로젝트를 SVN 저장소에 commit한다. jenkins를 이용해 빌드 및 배포하기 위함이다(ex. svn://[SVN URL]/repository/[Project Name]).
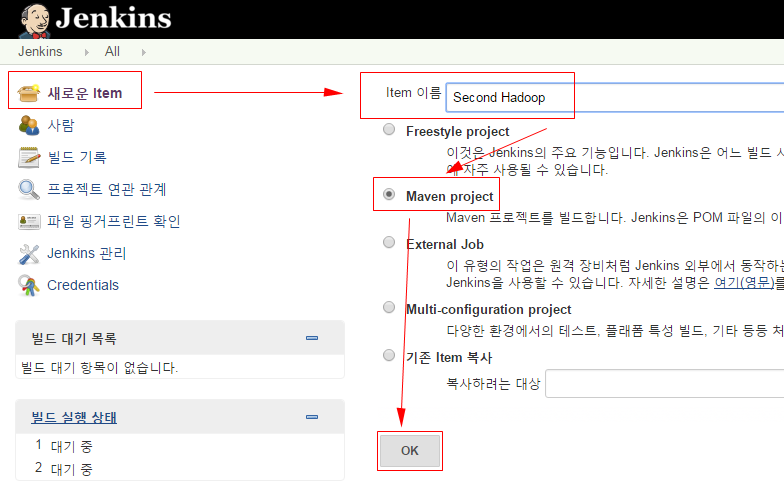
■ Jenkins에서 새로운 Item을 선택하고 Item 이름에 임의의 이름을 입력하고 Maven project를 선택후 OK버튼을 선택한다.
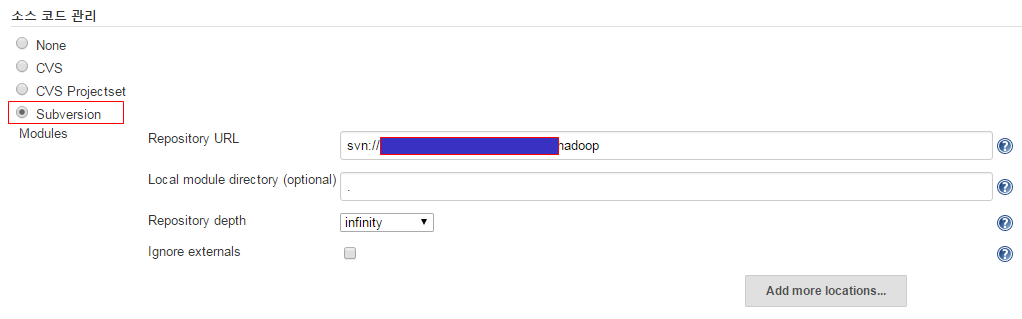
■ 소스 코드 관리 라디오 버튼을 선택하고 Repository URL에 SVN주소를 입력한다. 필요시 SVN ID, Password를 같이 등록한다.
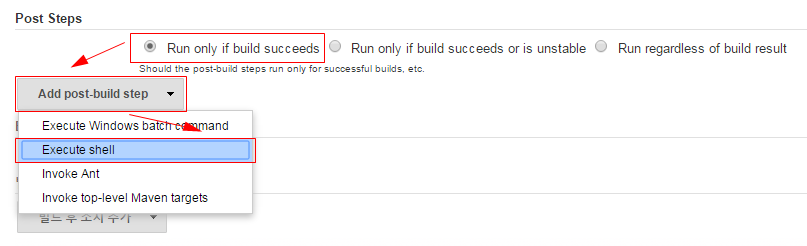
■ Post Steps에서 Run only if build succeeds 라디오 버튼을 선택하고 Add post-build step 셀렉트 박스에서 Execute shell 을 선택한다.
■ Execute shell의 Command에 scp 명령어를 이용하여 빌드된 jar 파일을 각 데이터 노드로 복사를 진행하는 스크립트를 입력한 후 저장 버튼을 입력하면 Jenkins에 신규 빌드 Item 등록이 완료된다.
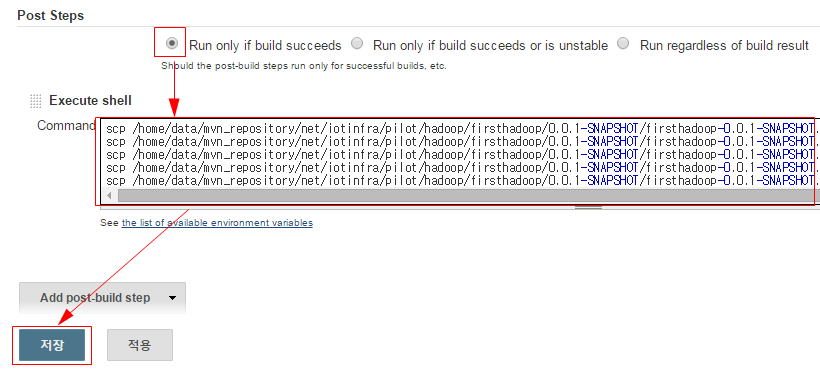
scp /home/data/mvn_repository/xxx/firsthadoop-0.0.1-SNAPSHOT.jar centos01:/home/data/hadoop/workjar scp /home/data/mvn_repository/xxx/firsthadoop-0.0.1-SNAPSHOT.jar centos02:/home/data/hadoop/workjar scp /home/data/mvn_repository/xxx/firsthadoop-0.0.1-SNAPSHOT.jar centos03:/home/data/hadoop/workjar scp /home/data/mvn_repository/xxx/firsthadoop-0.0.1-SNAPSHOT.jar centos04:/home/data/hadoop/workjar scp /home/data/mvn_repository/xxx/firsthadoop-0.0.1-SNAPSHOT.jar centos05:/home/data/hadoop/workjar
■ start-yarn.sh, start-dfs.sh 스크립트 실행해서 hadoop을 실행한다.
[nextman@centos01 data]$ /usr/local/hadoop-2.6.0/sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-nextman-resourcemanager-centos01.out centos03: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-nextman-nodemanager-centos03.out centos04: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-nextman-nodemanager-centos04.out centos02: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-nextman-nodemanager-centos02.out centos05: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-nextman-nodemanager-centos05.out [nextman@centos01 data]$ /usr/local/hadoop-2.6.0/sbin/start-dfs.sh Starting namenodes on [centos01] centos01: starting namenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-nextman-namenode-centos01.out centos04: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-nextman-datanode-centos04.out centos02: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-nextman-datanode-centos02.out centos05: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-nextman-datanode-centos05.out centos03: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-nextman-datanode-centos03.out Starting secondary namenodes [centos02] centos02: starting secondarynamenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-nextman-secondarynamenode-centos02.out
■ 작업용 디렉토리(/home/data/hadoop/dfs/data/wordcount2, /home/data/hadoop/dfs/data/wordcount2/input, /home/data/hadoop/dfs/data/wordcount2/output)를 생성하고 포멧한다.
[nextman@centos01 data]$ pwd /home/data/hadoop/dfs/data [nextman@centos01 data]$ mkdir /home/data/hadoop/dfs/data/wordcount2 [nextman@centos01 data]$ mkdir /home/data/hadoop/dfs/data/wordcount2/input [nextman@centos01 data]$ mkdir /home/data/hadoop/dfs/data/wordcount2/output [nextman@centos01 data]$ hadoop fs -mkdir /home/data/hadoop/dfs/data/wordcount2 [nextman@centos01 data]$ hadoop fs -mkdir /home/data/hadoop/dfs/data/wordcount2/input [nextman@centos01 data]$ hadoop fs -mkdir /home/data/hadoop/dfs/data/wordcount2/output
■ 샘플 작업용 파일(README.txt)를 hadoop input 디렉토리에 복사하고 파일 리스트를 확인한다.
[nextman@centos01 data]$ hadoop fs -copyFromLocal /home/nextman/tmp/README.txt /home/data/hadoop/dfs/data/wordcount2/input [nextman@centos01 data]$ hadoop fs -ls /home/data/hadoop/dfs/data/wordcount2/input Found 1 items -rw-r--r-- 3 nextman supergroup 34634343 2016-03-01 23:00 /home/data/hadoop/dfs/data/wordcount2/input/README.txt
■ hadoop mapreduce 작업 실행하고 출력 파일(/home/data/hadoop/dfs/data/wordcount2/output 디렉토리)들을 확인한다.
[nextman@centos01 data]$ hadoop fs -rm -r /data/wordcount/output [nextman@centos01 data]$ hadoop jar firsthadoop-0.0.1-SNAPSHOT.jar net.iotinfra.pilot.hadoop.WordCount /data/wordcount/input /data/wordcount/output ... 생략 16/03/01 23:10:39 INFO mapreduce.Job: Job job_local1220506562_0001 completed successfully 16/03/01 23:10:39 INFO mapreduce.Job: Counters: 38 File System Counters FILE: Number of bytes read=22167730 ... 생략 HDFS: Number of write operations=4 Map-Reduce Framework Map input records=308494 ... 생략 Total committed heap usage (bytes)=288366592 Shuffle Errors ... 생략 File Output Format Counters Bytes Written=4719844 [nextman@centos01 data]$ hadoop fs -ls /home/data/hadoop/dfs/data/wordcount2/output Found 2 items -rw-r--r-- 3 nextman supergroup 0 2016-03-01 23:10 /home/data/hadoop/dfs/data/wordcount2/output/_SUCCESS -rw-r--r-- 3 nextman supergroup 4719844 2016-03-01 23:10 /home/data/hadoop/dfs/data/wordcount2/output/part-r-00000
■ 결과 내용 확인, 조금씩 보고자 할 때 more를 추가한다.(‘| more’)
[nextman@centos01 output]$ hadoop fs -cat /home/data/hadoop/dfs/data/wordcount2/output/part-r-00000 | more
- hadoop fs 명령어 정리 2016년 3월 9일
- Eclipse Hadoop WordCount 2016년 3월 1일
- Missing artifact jdk.tools:jdk.tools.:jar:1.x 2016년 3월 1일
- localhost: Error: JAVA_HOME is not set and could not be found. 2016년 2월 28일
- Hadoop 완전분산 설치 2016년 2월 28일
- hadoop standalone mode install – 하둡 단일모드 설치 2014년 9월 13일